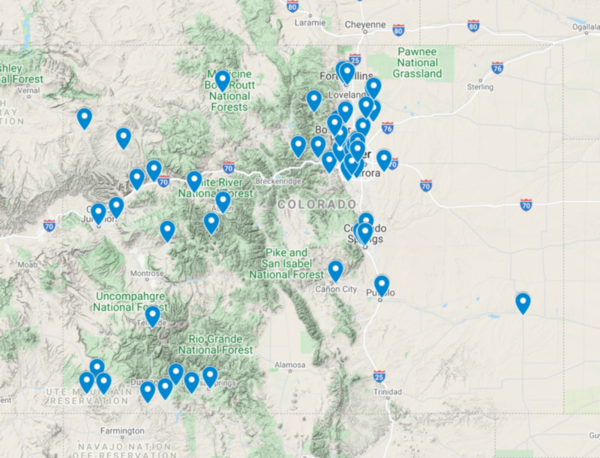
Emissions from oil and natural gas (O&G) wells such as nitrogen dioxide (NO2), volatile organic compounds (VOCs), and ozone (O3) can severely impact the health of communities located near wells. In this study, we used O&G activity and wind-carried emissions to quantify the extent to which O&G wells affect the air quality of nearby communities, revealing that NO2, NOx, and NO are correlated to O&G activity. We then developed a novel land use regression (LUR) model using machine learning based on O&G prevalence to predict emissions.
Image credit: Chunduri, Srinivas and McMahan, 2024.
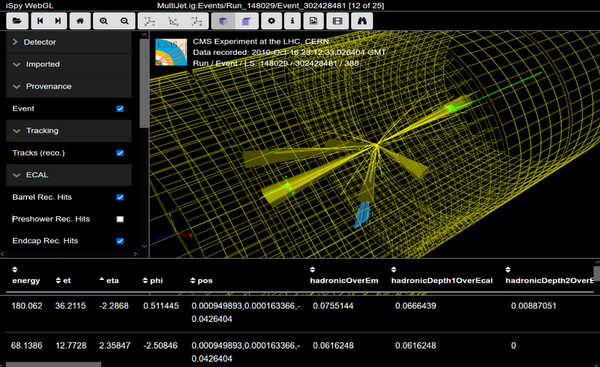
Collisions of heavy ions, such as muons result in jets and noise. In high-energy particle physics, researchers use jets as crucial event-shaped observable objects to determine the properties of a collision. However, many ionic collisions result in large amounts of energy lost as noise, thus reducing the efficiency of collisions with heavy ions. The purpose of our study is to analyze the relationships between properties of muons in a dimuon collision to optimize conditions of dimuon collisions and minimize the noise lost. We used principles of Newtonian mechanics at the particle level, allowing us to further analyze different models. We used simple Python algorithms as well as linear regression models with tools such as sci-kit Learn, NumPy, and Pandas to help analyze our results. We hypothesized that since the invariant mass, the energy, and the resultant momentum vector are correlated with noise, if we constrain these inputs optimally, there will be scenarios in which the noise of the heavy-ion collision is minimized.
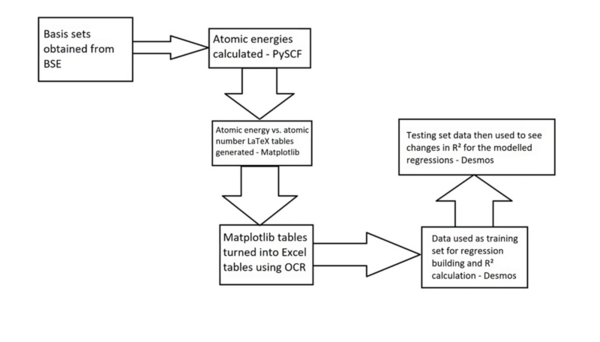
The energy of an atom is extremely useful in nuclear physics and reaction mechanism pathway determination but is challenging to compute. This work aimed to synthesize regression models for Pople Gaussian expansions of Slater-type Orbitals (STO-nG) atomic energy vs. atomic number scatter plots to allow for easy approximation of atomic energies without using computational chemistry methods. The data indicated that of the regressions, sinusoidal regressions most aptly modeled the scatter plots.
Here, seeking to understand the correlation of 50 of the most important economic indicators with inflation, the authors used a rolling linear regression to identify indicators with the most significant correlation with the Month over Month Consumer Price Index Seasonally Adjusted (CPI). Ultimately the concluded that the average gasoline price, U.S. import price index, and 5-year market expected inflation had the most significant correlation with the CPI.
Here, the authors investigated the most efficient way to position magnets to hold the most pieces of paper on the surface of a refrigerator. They used a regression model along with an artificial neural network to identify the most efficient positions of four magnets to be at the vertices of a rectangle.
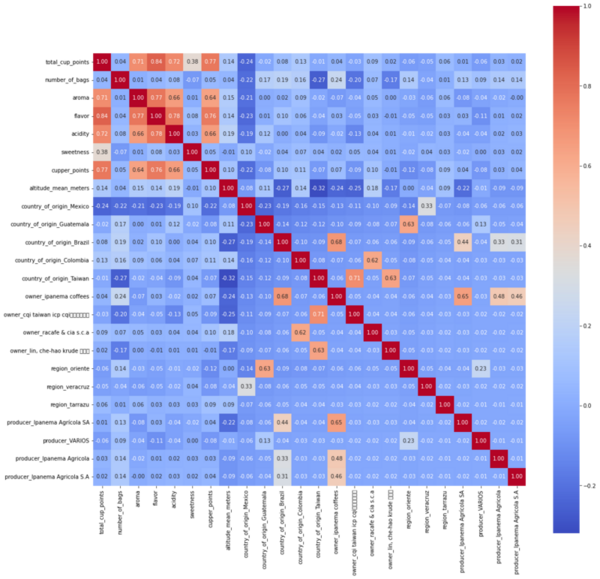
This study explores the factors that influence coffee quality ratings using data from the Coffee Quality Institute. Through a regression model based on gradient descent, the authors aimed to predict coffee ratings (total cup points) and hypothesized that sweetness and the coffee producer would be the most influential factors.
In this article, the authors identify the characteristics that make a book a best-seller. Knowing what, besides content, predicts the success of a book can help publishers maximize the success of their print products.
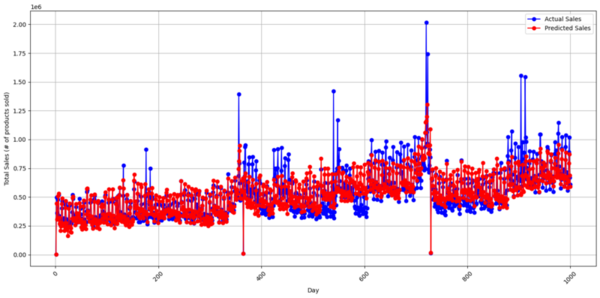
This study uses interpretable machine learning models, lasso and ridge regression with Shapley analysis, to identify key sales drivers for Corporación Favorita, Ecuador’s largest grocery chain. The results show that macroeconomic factors, especially labor force size, have the greatest impact on sales, though geographic and seasonal variables like city altitude and holiday proximity also play important roles. These insights can help businesses focus on the most influential market conditions to enhance competitiveness and profitability.
Sequence accessibility is an important factor affecting gene expression. Sequence accessibility or openness impacts the likelihood that a gene is transcribed and translated into a protein and performs functions and manifests traits. There are many potential factors that affect the accessibility of a gene. In this study, our hypothesis was that the content of nucleotides in a genetic sequence predicts its accessibility. Using a machine learning linear regression model, we studied the relationship between nucleotide content and accessibility.
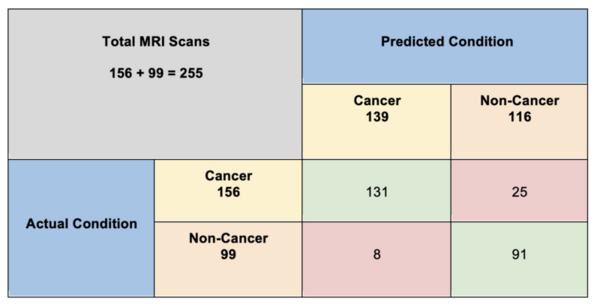
AI analysis of brain scans offers promise for helping doctors diagnose brain tumors. Haider and Drosis explore this field by developing machine learning models that classify brain scans as "cancer" or "non-cancer" diagnoses.