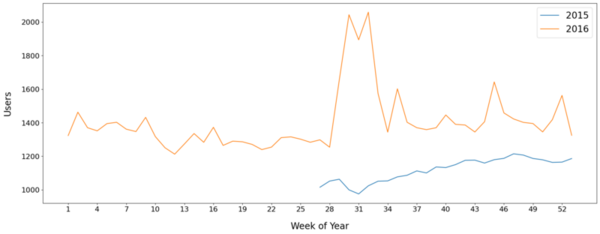
The authors looked at ways to provide better forecasting on website traffic. They found that deep learning models performed better than statistical models.
Read More...Deep sequential models versus statistical models for web traffic forecasting
The authors looked at ways to provide better forecasting on website traffic. They found that deep learning models performed better than statistical models.
Read More...Monitoring drought using explainable statistical machine learning models
Droughts have a wide range of effects, from ecosystems failing and crops dying, to increased illness and decreased water quality. Drought prediction is important because it can help communities, businesses, and governments plan and prepare for these detrimental effects. This study predicts drought conditions by using predictable weather patterns in machine learning models.
Read More...Jet optimization using a hybrid multivariate regression model and statistical methods in dimuon collisions
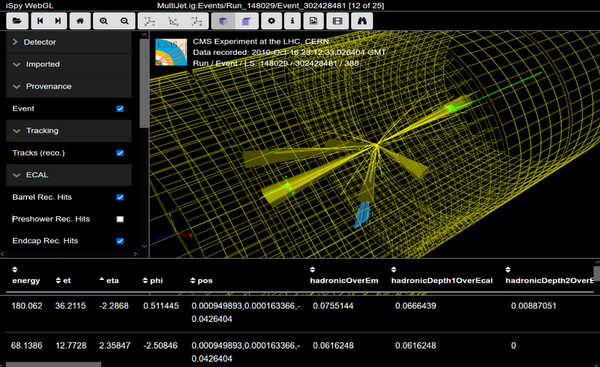
Collisions of heavy ions, such as muons result in jets and noise. In high-energy particle physics, researchers use jets as crucial event-shaped observable objects to determine the properties of a collision. However, many ionic collisions result in large amounts of energy lost as noise, thus reducing the efficiency of collisions with heavy ions. The purpose of our study is to analyze the relationships between properties of muons in a dimuon collision to optimize conditions of dimuon collisions and minimize the noise lost. We used principles of Newtonian mechanics at the particle level, allowing us to further analyze different models. We used simple Python algorithms as well as linear regression models with tools such as sci-kit Learn, NumPy, and Pandas to help analyze our results. We hypothesized that since the invariant mass, the energy, and the resultant momentum vector are correlated with noise, if we constrain these inputs optimally, there will be scenarios in which the noise of the heavy-ion collision is minimized.
Read More...The effect of joint angle differences on blade velocity in elite and novice saber fencers: A kinematic study

Here, recognizing that years of training in saber fencing could expectedly result in optimized movements that result in elite skill levels, the authors used motion tracking and statistical analysis to assess the difference in velocity and blade tip velocity of novice and elite fencers during a vertical blade thrust. They found statistically significant differences in blade tip velocity and elbow joint angle kinematics.
Read More...An analysis of junior rower performance and how it is affected by rower's features

In this study, with consideration for the increasing participation of high school students in indoor rowing, the authors analyzed World Indoor Rowing Championship data. Statistical analysis revealed two key features that can determine the performance of a rower as well as increasing competitiveness in nearly all categories considered. They conclude by offering a 2000-meter ergometer time distribution that can help junior rowers assess their current performance relative to the world competition.
Read More...Part of speech distributions for Grimm versus artificially generated fairy tales

Here, the authors wanted to explore mathematical paradoxes in which there are multiple contradictory interpretations or analyses for a problem. They used ChatGPT to generate a novel dataset of fairy tales. They found statistical differences between the artificially generated text and human produced text based on the distribution of parts of speech elements.
Read More...Sports Are Not Colorblind: The Role of Race and Segregation in NFL Positions

In this study, the authors conducted a statistical investigation into the history of position-based racial segregation in the NFL. Specifically, they focused on the cornerback position, which they hypothesized would be occupied disproportionately by black players due to their historical stereotyping as more suitable for positions requiring extreme athletic ability. Using publicly available datasets on the demographics of NFL players over the past several decades, they confirmed their hypothesis that the cornerback position is skewed towards black players. They additionally discovered that, unlike in the quarterback position, this trend has shown no sign of decreasing over time.
Read More...Locating carcinogenic per- and poly-fluoroalkyl substances in Santa Clarita groundwater
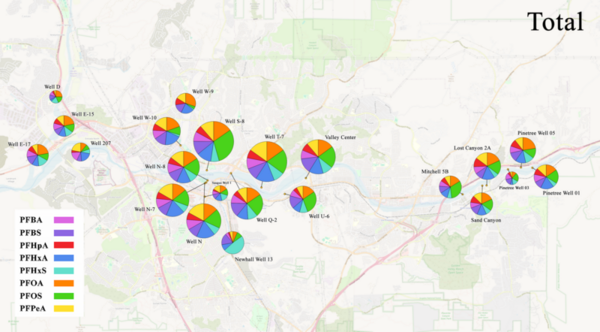
This study investigates PFAS contamination in Santa Clarita groundwater, focusing on potential sources. The study employs statistical analysis to assess data quality and trends which allowed them to identified domestic waste, fire extinguisher materials, and food packaging as the most likely sources of contamination.
Read More...Redefining and advancing tree disease diagnosis through VOC emission measurements

Here the authors investigated the use of an affordable gas sensor to detect volatile organic compound (VOC) emissions as an early indicator of tree disease, finding statistically significant differences in VOCs between diseased and non-diseased ash, beech, and maple trees. They suggest this sensor has potential for widespread early disease detection, but call for further research with larger sample sizes and diverse locations.
Read More...The characterization of quorum sensing trajectories of Vibrio fischeri using longitudinal data analytics
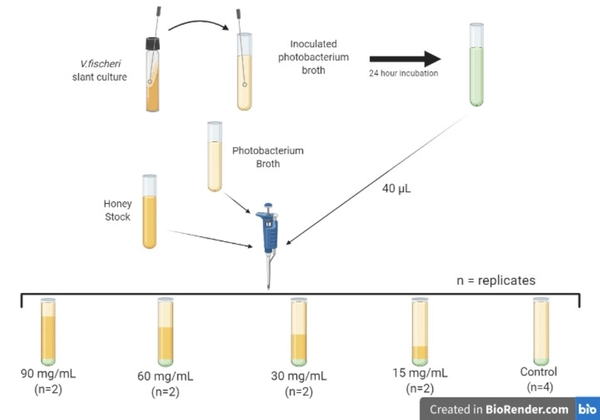
Quorum sensing (QS) is the process in which bacteria recognize and respond to the surrounding cell density, and it can be inhibited by certain antimicrobial substances. This study showed that illumination intensity data is insufficient for evaluating QS activity without proper statistical modeling. It concluded that modeling illumination intensity through time provides a more accurate evaluation of QS activity than conventional cross-sectional analysis.
Read More...