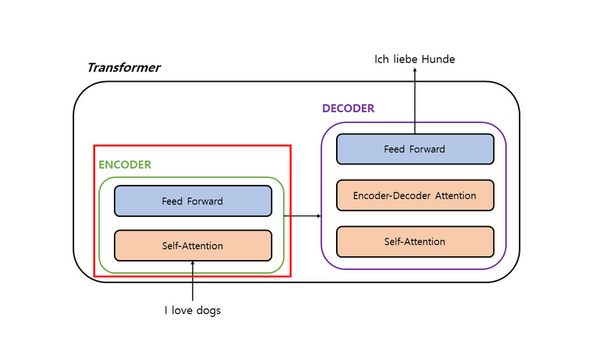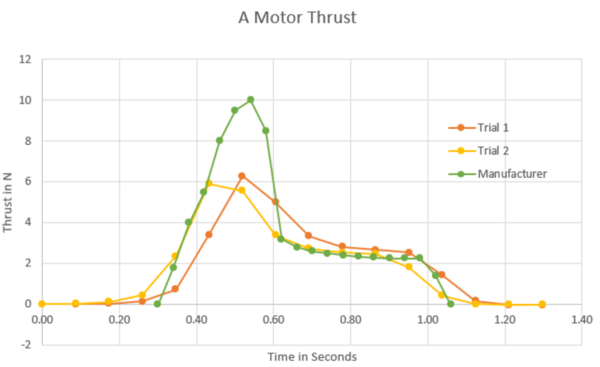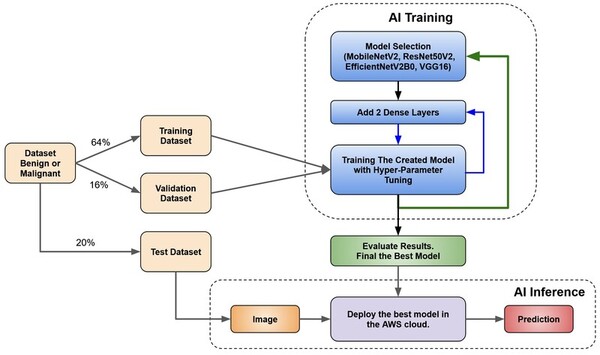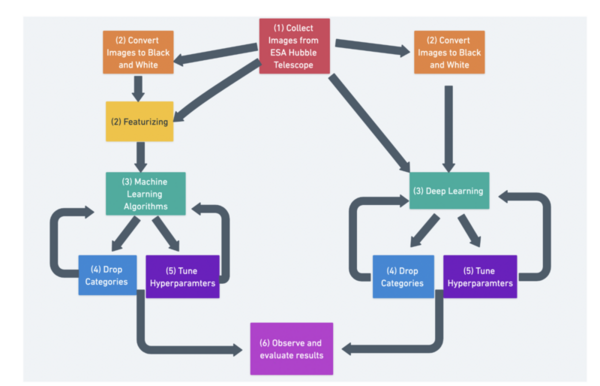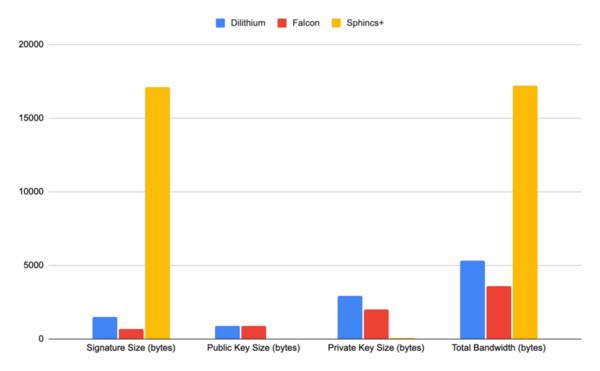
The advent of quantum computing will pose a substantial threat to the security of classical cryptographic methods, which could become vulnerable to quantum-based attacks. In response to this impending challenge, the field of post-quantum cryptography has emerged, aiming to develop algorithms that can withstand the computational power of quantum computers. This study addressed the pressing concern of classical cryptographic methods becoming vulnerable to quantum-based attacks due to the rise of quantum computing. The emergence of post-quantum cryptography has led to the development of new resistant algorithms. Our research focused on four quantum-resistant algorithms endorsed by America’s National Institute of Standards and Technology (NIST) in 2022: CRYSTALS-Kyber, CRYSTALS-Dilithium, FALCON, and SPHINCS+. This study evaluated the security, performance, and comparative attributes of the four algorithms, considering factors such as key size, encryption/decryption speed, and complexity. Comparative analyses against each other and existing quantum-resistant algorithms provided insights into the strengths and weaknesses of each program. This research explored potential applications and future directions in the realm of quantum-resistant cryptography. Our findings concluded that the NIST algorithms were substantially more effective and efficient compared to classical cryptographic algorithms. Ultimately, this work underscored the need to adapt cryptographic techniques in the face of advancing quantum computing capabilities, offering valuable insights for researchers and practitioners in the field. Implementing NIST-endorsed quantum-resistant algorithms substantially reduced the vulnerability of cryptographic systems to quantum-based attacks compared to classical cryptographic methods.
Read More...