Physical therapy, especially for patients with spinal cord injuries, can be a difficult and tedious experience. This can result in negative health outcomes, such as patients dropping out of physical therapy or developing additional health problems. In this study, the authors develop and test a potential solution to these challenges: a mixed reality game called Skyfarer that replaces a standard physical therapy regimen with an immersive experience that can be shared with their friends and family. The findings of this study suggest that mixed reality games such as Skyfarer could be effective alternatives to conventional physical therapy.
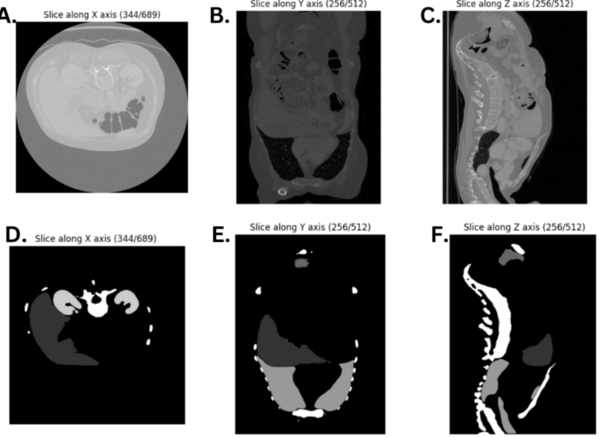
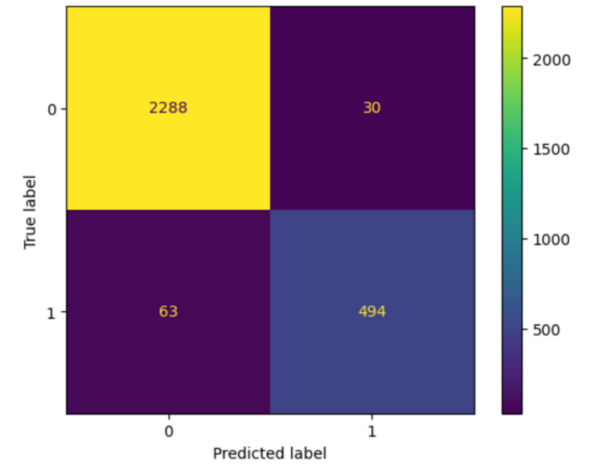
The authors looked at different models of semantic segmentation to determine which may be best used in the future for segmentation of CT scans to help diagnose certain conditions.
Here, the authors wanted to explore mathematical paradoxes in which there are multiple contradictory interpretations or analyses for a problem. They used ChatGPT to generate a novel dataset of fairy tales. They found statistical differences between the artificially generated text and human produced text based on the distribution of parts of speech elements.
While remarkable in its ability to mirror human cognition, machine learning and its associated algorithms often require extensive data to prove effective in completing tasks. However, data is not always plentiful, with unpredictable events occurring throughout our daily lives that require flexibility by artificial intelligence utilized in technology such as personal assistants and self-driving vehicles. Driven by the need for AI to complete tasks without extensive training, the researchers in this article use fluid intelligence assessments to develop an algorithm capable of generalization and abstraction. By forgoing prioritization on skill-based training, this article demonstrates the potential of focusing on a more generalized cognitive ability for artificial intelligence, proving more flexible and thus human-like in solving unique tasks than skill-focused algorithms.
The mountain chain of the Western Ghats on the Indian peninsula, a UNESCO World Heritage site, is home to about 200 frog species, 89 of which are endemic. Distinctive to each frog species, their vocalizations can be used for species recognition. Manually surveying frogs at night during the rain in elephant and big cat forests is difficult, so being able to autonomously record ambient soundscapes and identify species is essential. An effective machine learning (ML) species classifier requires substantial training data from this area. The goal of this study was to assess data augmentation techniques on a dataset of frog vocalizations from this region, which has a minimal number of audio recordings per species. Consequently, enhancing an ML model’s performance with limited data is necessary. We analyzed the effects of four data augmentation techniques (Time Shifting, Noise Injection, Spectral Augmentation, and Test-Time Augmentation) individually and their combined effect on the frog vocalization data and the public environmental sounds dataset (ESC-50). The effect of combined data augmentation techniques improved the model's relative accuracy as the size of the dataset decreased. The combination of all four techniques improved the ML model’s classification accuracy on the frog calls dataset by 94%. This study established a data augmentation approach to maximize the classification accuracy with sparse data of frog call recordings, thereby creating a possibility to build a real-world automated field frog species identifier system. Such a system can significantly help in the conservation of frog species in this vital biodiversity hotspot.
Auto-Regressive Integrated Moving Average (ARIMA) models are known for their influence and application on time series data. This statistical analysis model uses time series data to depict future trends or values: a key contributor to crime mapping algorithms. However, the models may not function to their true potential when analyzing data with many different patterns. In order to determine the potential of ARIMA models, our research will test the model on irregularities in the data. Our team hypothesizes that the ARIMA model will be able to adapt to the different irregularities in the data that do not correspond to a certain trend or pattern. Using crime theft data and an ARIMA model, we determined the results of the ARIMA model’s forecast and how the accuracy differed on different days with irregularities in crime.
The death of George Floyd has shed light on the disproportionate level of policing affecting non-Whites in the United States of America. To explore whether non-Whites were disproportionately targetted by New York City's "Stop and Frisk" policy, the authors analyze publicly available data on the practice between 2003-2019. Their results suggest African Americans were indeed more likely to be stopped by the police until 2012, after which there was some improvement.
Image credit: Meister, Horvath, and Brown de Colstoun
This manuscript investigates the urban heat island (UHI) effect by utilizing two satellite datasets: Landsat (high spatial resolution, lower temporal resolution) and MODIS (lower spatial resolution, high temporal resolution). The authors hypothesized that Landsat would provide better spatial detail, while MODIS would better capture temporal variations. Their analysis in the Washington D.C.–Baltimore region supports these hypotheses, demonstrating that Landsat offers finer spatial details, whereas MODIS provides more consistent seasonal patterns and better detects heatwave frequencies.