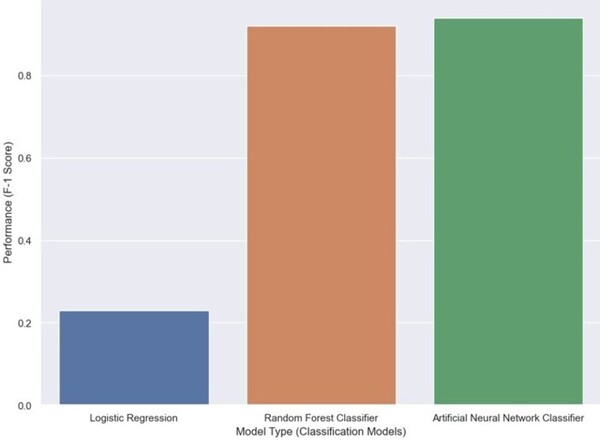
The authors looked at the ability of different machine learning algorithms to predict the level of financial corruption in different countries.
Read More...Predicting and explaining illicit financial flows in developing countries: A machine learning approach
The authors looked at the ability of different machine learning algorithms to predict the level of financial corruption in different countries.
Read More...Applying machine learning to breast cancer diagnosis: A high school student’s exploration using R
The authors combine fine needle aspiration biopsy and machine learning algorithms to develop a breast cancer detection method suitable for resource-constrained regions that lack access to mammograms.
Read More...AeroPurify: Autonomous air filtration UAV using real-time 3-D Monte Carlo gradient search

Here the authors present an autonomous drone air filtration system that uses a novel algorithm, the gradient ascent ML particle filter (GA/MLPF), to efficiently locate and mitigate outdoor air pollution. They demonstrate that their GA/MLPF algorithm is significantly more efficient than the conventional gradient ascent algorithm, reducing both the time and number of waypoints needed to find the source of pollution.
Read More...Estimation of Reproduction Number of Influenza in Greece using SIR Model
In this study, we developed an algorithm to estimate the contact rate and the average infectious period of influenza using a Susceptible, Infected, and Recovered (SIR) epidemic model. The parameters in this model were estimated using data on infected Greek individuals collected from the National Public Health Organization. Our model labeled influenza as an epidemic with a basic reproduction value greater than one.
Read More...Predicting clogs in water pipelines using sound sensors and machine learning linear regression
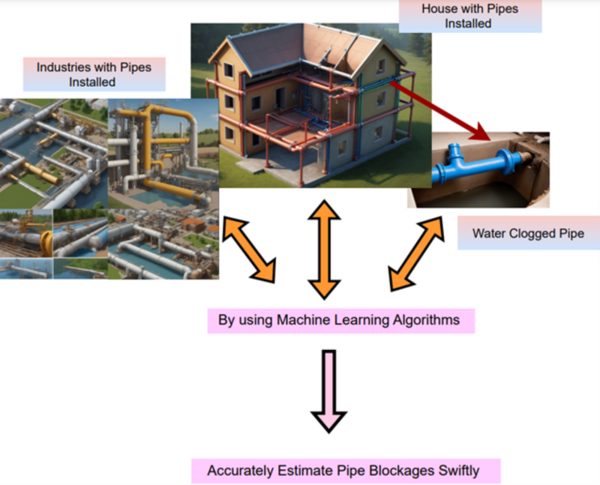
The authors looked the ability of sound sensors to predict clogged pipes when the sound intensity data is run through a machine learning algorithm.
Read More...Demographic indicators of voter shift between 2016 and 2020 presidential elections

In this study, the authors investigate the demographic indicators for voter shift between the 2016 and 2020 presidential elections based on demographic data put through a K-nearest neighbors classification algorithm and Principal Component Analysis.
Read More...Virtual Screening of Cutibacterium acnes Antibacterial Agent Using Natural Compounds Database
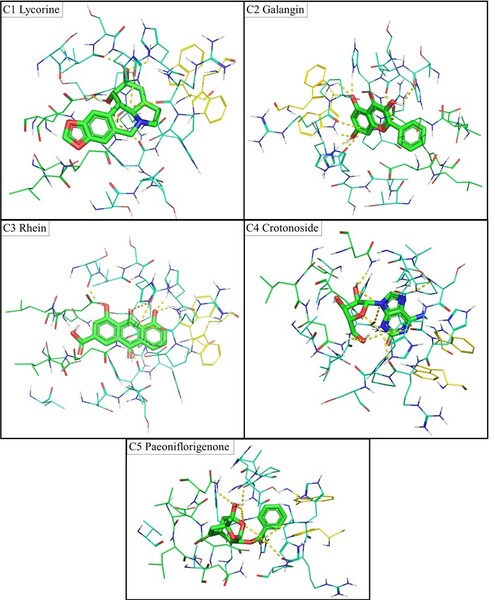
A common form of Acne is caused by a species of bacterium called Cutibacterium acnes. By using a predictive algorithm and structural analysis, the authors identified 5 small molecules with high affinity to growth factors in Catibacterium acnes. This has potential implications for supplemental skincare products.
Read More...Machine learning for the diagnosis of malaria: a pilot study of transfer learning techniques
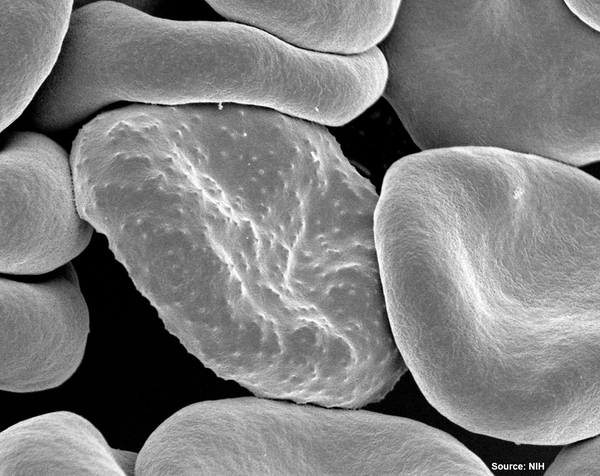
The diagnosis of malaria remains one of the major hurdles to eradicating the disease, especially among poorer populations. Here, the authors use machine learning to improve the accuracy of deep learning algorithms that automate the diagnosis of malaria using images of blood smears from patients, which could make diagnosis easier and faster for many.
Read More...Depression detection in social media text: leveraging machine learning for effective screening
Depression affects millions globally, yet identifying symptoms remains challenging. This study explored detecting depression-related patterns in social media texts using natural language processing and machine learning algorithms, including decision trees and random forests. Our findings suggest that analyzing online text activity can serve as a viable method for screening mental disorders, potentially improving diagnosis accuracy by incorporating both physical and psychological indicators.
Read More...Utilizing meteorological data and machine learning to predict and reduce the spread of California wildfires

This study hypothesized that a machine learning model could accurately predict the severity of California wildfires and determine the most influential meteorological factors. It utilized a custom dataset with information from the World Weather Online API and a Kaggle dataset of wildfires in California from 2013-2020. The developed algorithms classified fires into seven categories with promising accuracy (around 55 percent). They found that higher temperatures, lower humidity, lower dew point, higher wind gusts, and higher wind speeds are the most significant contributors to the spread of a wildfire. This tool could vastly improve the efficiency and preparedness of firefighters as they deal with wildfires.
Read More...