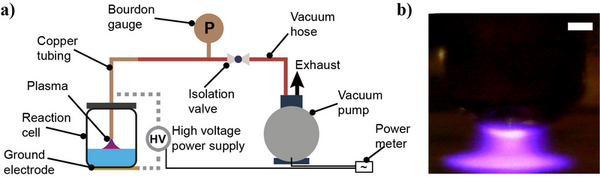
The authors looked at energy efficient ways to generate small nitrogenous compounds.
Read More...Nonthermal nitrogen fixation with air and water by using a low-pressure plasma
SpottingDiffusion: Using transfer learning to detect Latent Diffusion Model-synthesized images
Voltage, power, and energy production of a Shewanella oneidensis biofilm microbial fuel cell in microgravity
.PNG)
The authors looked at the ability of Shewanella oneidensis to generate energy in a microbial fuel cell under varying conditions. They found that the S. Onedensis biofilm was able to produce energy in microgravity and that one of the biggest factors that limited energy production was a decrease in growth medium present.
Read More...Comparison of three large language models as middle school math tutoring assistants

Middle school math forms the basis for advanced mathematical courses leading up to the university level. Large language models (LLMs) have the potential to power next-generation educational technologies, acting as digital tutors to students. The main objective of this study was to determine whether LLMs like ChatGPT, Bard, and Llama 2 can serve as reliable middle school math tutoring assistants on three tutoring tasks: hint generation, comprehensive solution, and exercise creation.
Read More...Observing food and density effects on the reproductive strategies of Heterandria formosa
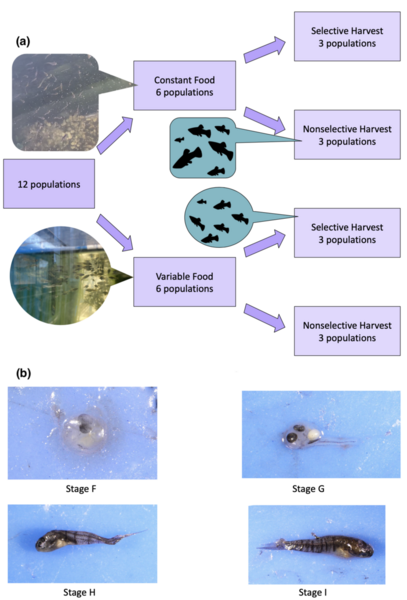
The authors looked at the impact of different harvest and feeding treatments on Heterandria formosa over three generations as a model for changes in marine ecosystems.
Read More...PID and fuzzy logic optimization of the pitch control of wind turbines
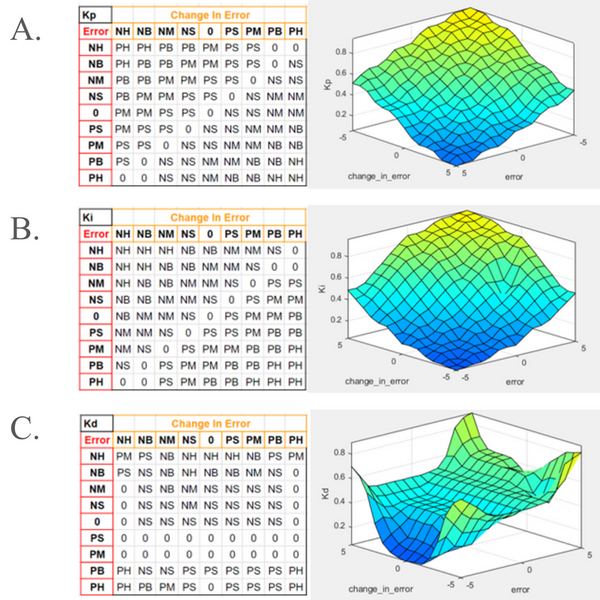
Wind turbines are a valuable source of renewable energy, but face challenges related to unpredictable wind speed. The turbine must be able to control its angle to catch enough wind to generate electricity, while avoiding excess wind that may damage the turbine. Zhou and Wang explore different types of smart turbine controllers to see which appears optimal for electricity generation.
Read More...Photometric analysis of Type Ia Supernova 2023jvj

Here the authors conducted a photometric analysis of Supernova (SN) 20234jvj. Through generating a light curve, they determined SN 2023jvj to be a Type Ia supernova located approximately 1.246e8 parasecs away from Earth.
Read More...Pruning replay buffer for efficient training of deep reinforcement learning

Reinforcement learning (RL) is a form of machine learning that can be harnessed to develop artificial intelligence by exposing the intelligence to multiple generations of data. The study demonstrates how reply buffer reward mechanics can inform the creation of new pruning methods to improve RL efficiency.
Read More...Evaluating the feasibility of SMILES-based autoencoders for drug discovery
The authors investigate the ability of machine learning models to developing new drug-like molecules by learning desired chemical properties versus simply generating molecules that similar to those in the training set.
Read More...Optimizing airfoil shape for small, low speed, unmanned gliders: A homemade investigation

Here, the authors sought to identify a method to optimize the lift generated by an airfoil based solely on its shape. By beginning with a Bernoullian model to predict an optimized wing shape, the authors then tested their model against other possible shapes by constructing them from Styrofoam and testing them in a small wind tunnel. Contrary to their hypothesis, they found their expected optimal airfoil shape did not result in the greatest lift generation. They attributed this to a variety of confounding variables and concluded that their results pointed to a correlation between airfoil shape and lift generation.
Read More...