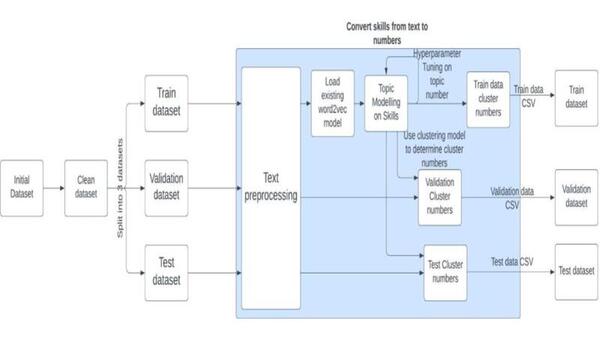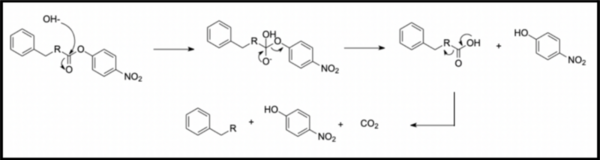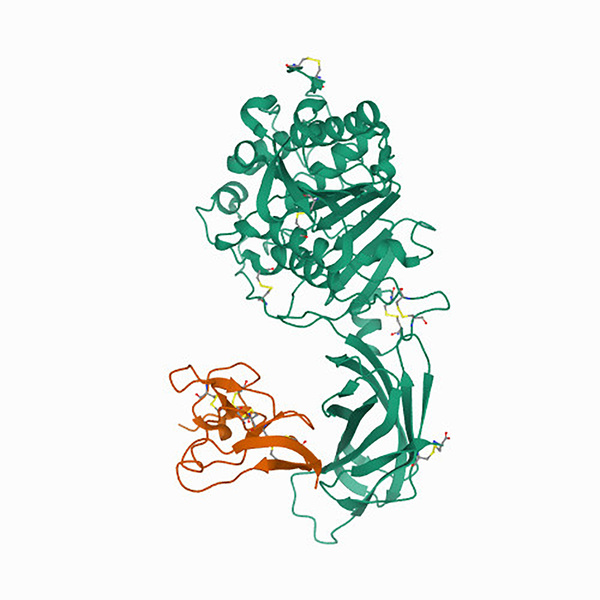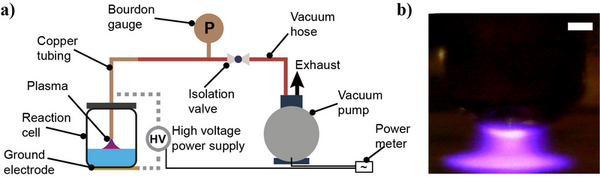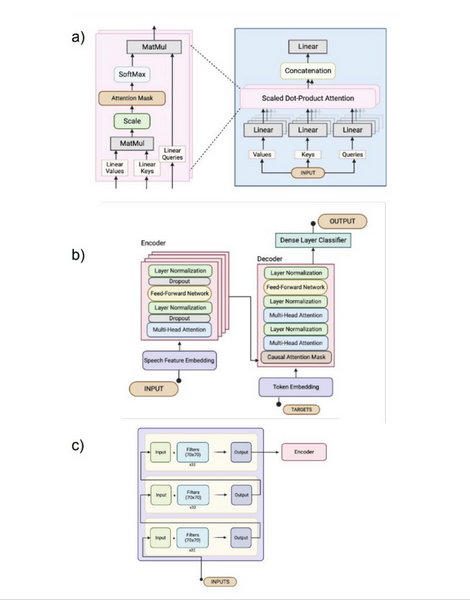
Brain-Computer Interface (BCI) allows users, especially those with paralysis, to control devices through brain activity. This study explored using a custom transformer model to decode neural signals into handwritten text for individuals with limited motor skills, comparing its performance to a traditional RNN-based BCI.
Read More...