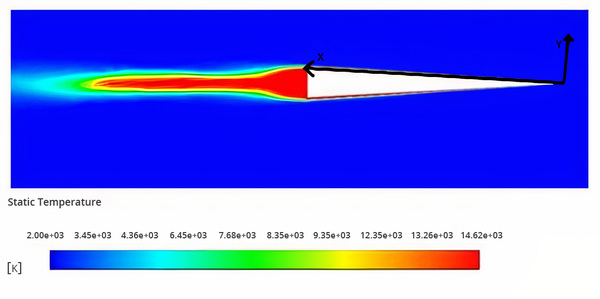
Oil spills are one of the most devastating events for marine life. Finding ways to clean up oil spills without the need for harsh chemicals could help decrease the negative impact of such spills. Here the authors demonstrate that using a combination of several biodegradable substances can effectively adsorb oil in seawater in a laboratory setting. They suggest further exploring the potential of such a combination as a possible alternative to commonly-used non-biodegradable substances in oil spill management.
Read More...