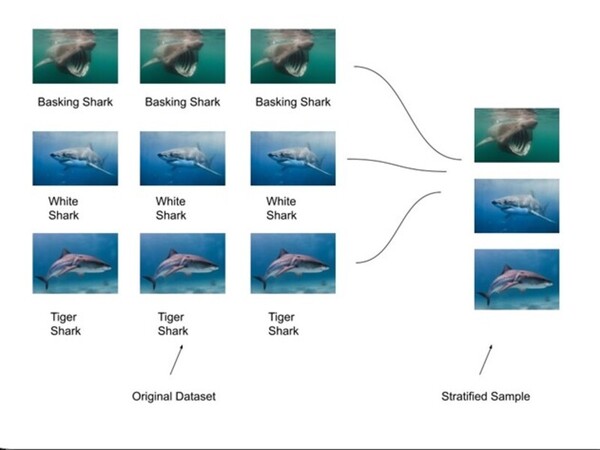
The challenge of accurately identifying shark species is crucial for biodiversity monitoring but is often hindered by time-consuming and labor-intensive manual methods. To address this, SharkNet, a CNN model based on AlexNet, achieved 93% accuracy in classifying shark species using a limited dataset of 1,400 images across 14 species. SharkNet offers a more efficient and reliable solution for marine biologists and conservationists in species identification and environmental monitoring.
Read More...


.jpg)