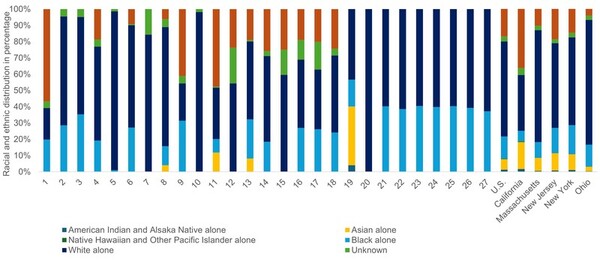
The authors analyzed racial and ethnic representation in studies on PFAS and neurological health outcomes.
Read More...Population demographic patterns in PFAS-neurological health research
The authors analyzed racial and ethnic representation in studies on PFAS and neurological health outcomes.
Read More...High school students’ perceptions of third-party tracking and personalization
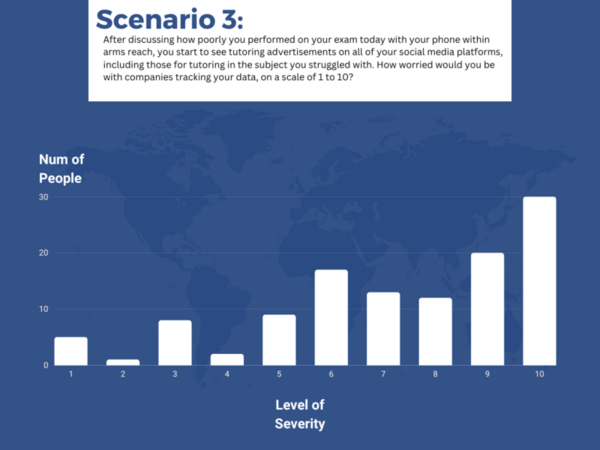
The authors looked at student perception on various situations involving third-party tracking to personalize recommendations.
Read More...The effects of varied N-acetylcysteine concentration and electronegativity on bovine mucus hydrolysis
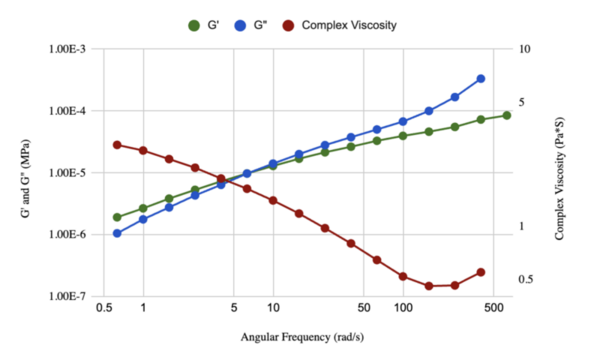
The authors evaluated the effect of concentration and variant of N-Acetylcysteine in hydrolyzing mucus.
Read More...Maternal mortality rates in the United States correlated with social determinants of health

This article helps in understanding the effect of various social determinants on maternal mortality in the United States. It explains the relationship between maternal mortality rates and factors like race, income, education, and health insurance access.
Read More...The Dependence of CO2 Removal Efficiency on its Injection Speed into Water
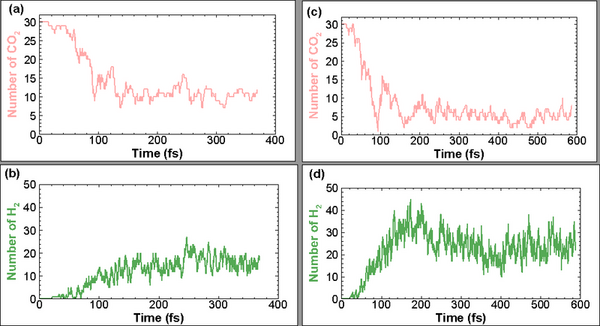
Recent research confirms that climate change, driven by CO2 emissions from burning fossil fuels, poses a significant threat to humanity. In response, authors explore methods to remove CO2 from the atmosphere, including breaking its molecular bonds through high-speed collisions.
Read More...Identifying shark species using an AlexNet CNN model
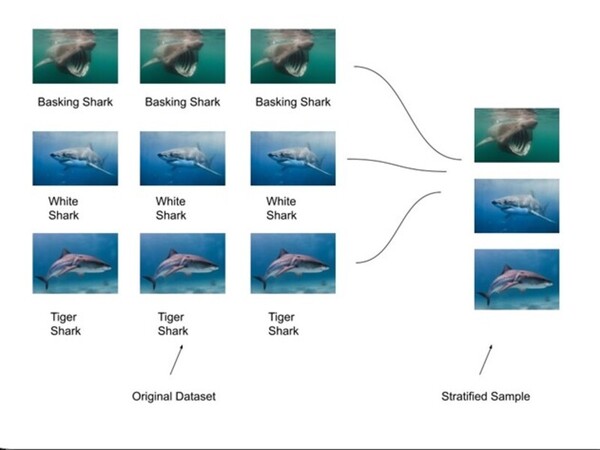
The challenge of accurately identifying shark species is crucial for biodiversity monitoring but is often hindered by time-consuming and labor-intensive manual methods. To address this, SharkNet, a CNN model based on AlexNet, achieved 93% accuracy in classifying shark species using a limited dataset of 1,400 images across 14 species. SharkNet offers a more efficient and reliable solution for marine biologists and conservationists in species identification and environmental monitoring.
Read More...Does language familiarity affect typing speed?

In cognitive psychology, typed responses are used to assess thinking skills and creativity, but research on factors influencing typing speed is limited. This study examined how language familiarity affects typing speed, hypothesizing that familiarity with a language would correlate with faster typing. Participants typed faster in English than Latin, with those unfamiliar with Latin showing a larger discrepancy between the two languages, though Latin education level did not significantly impact typing speed, highlighting the role of language familiarity in typing performance.
Read More...Evaluating the predicted eruption times of geysers in Yellowstone National Park
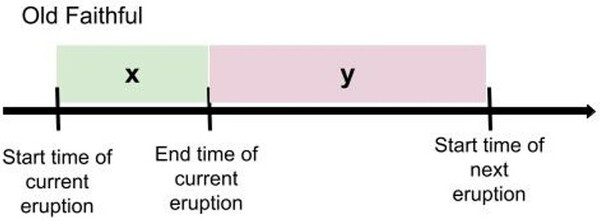
The authors compare the predicted versus actual geyser eruption times for the Old Faithful and Beehive Geysers at Yellowstone National Park.
Read More...Predictions of neural control deficits in elders with subjective memory complaints and Alzheimer’s disease
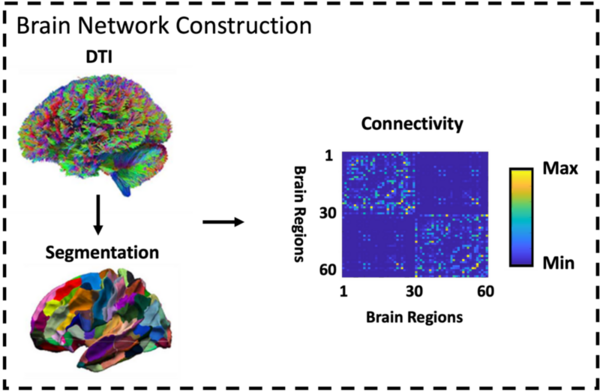
The authors compare neuroimaging datasets to identify potential new biomarkers for earlier detection of Alzheimer's disease.
Read More...Flight paths over greenspace in major United States airports

Greenspaces (urban and wetland areas that contain vegetation) are beneficial to reducing pollution, while airplanes are a highly-polluting method of transportation. The authors examine the intersection of these two environmental factors by processing satellite images to reveal what percentage of flight paths go over greenspaces at major US airports.
Read More...