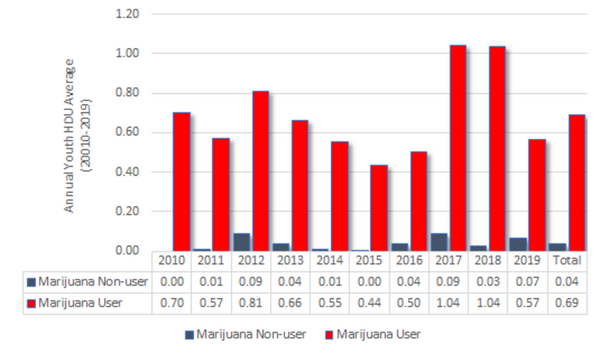
The authors looked at whether youth use of marijuana related to later high-risk drug use. Using survey data from 2010-2019 they found that youth marijuana use did correlate to an increased risk of high-risk drug use.
Read More...The effect of youth marijuana use on high-risk drug use: Examining gateway and substitution hypothesis
The authors looked at whether youth use of marijuana related to later high-risk drug use. Using survey data from 2010-2019 they found that youth marijuana use did correlate to an increased risk of high-risk drug use.
Read More...Identifying factors, such as low sleep quality, that predict suicidal thoughts using machine learning
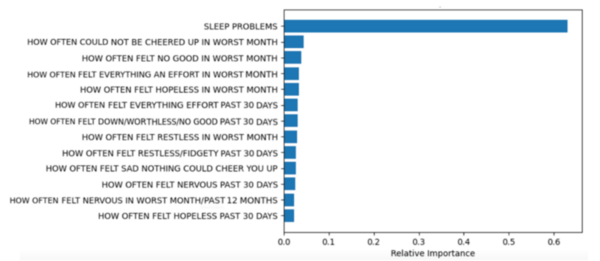
Sadly, around 800,000 people die by suicide worldwide each year. Dong and Pearce analyze health survey data to identify associations between suicidal ideation and relevant variables, such as sleep quality, hopelessness, and anxious behavior.
Read More...Identification of potential therapeutic targets for multiple myeloma by gene expression analysis
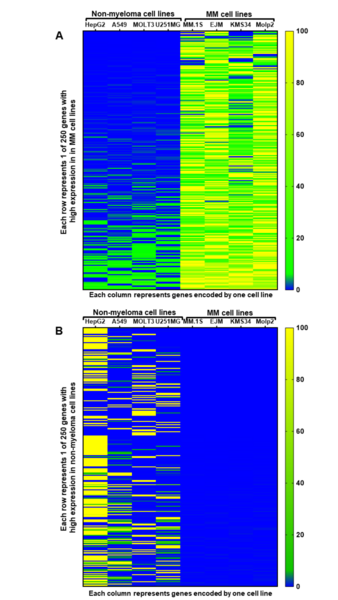
A central challenge of cancer therapy is identifying treatments that will effectively target cancer cells while minimizing effects on healthy cells. To identify potential targets for treating a multiple myeloma, a frequently incurable cancer, Kochenderfer and Kochenderfer analyze RNA sequencing data from the Cancer Cell Line Encyclopedia to find genes with high expression in multiple myeloma cells and low expression in normal tissues
Read More...Contribution of environmental factors to genetic variation in the Pacific white-sided dolphin

Here the authors sought to understand the effects of different variables that may be tied to pollution and climate change on genetic variation of Pacific white-sided dolphins, a species that is currently threatened by water pollution. Based on environmental data collected alongside a genetic distance matrix, they found that ocean currents had the most significant impact on the genetic diversity of Pacific white-sided dolphins along the Japanese coast.
Read More...Pruning replay buffer for efficient training of deep reinforcement learning

Reinforcement learning (RL) is a form of machine learning that can be harnessed to develop artificial intelligence by exposing the intelligence to multiple generations of data. The study demonstrates how reply buffer reward mechanics can inform the creation of new pruning methods to improve RL efficiency.
Read More...A comparison of use of the mobile electronic health record by medical providers based on clinical setting

The electronic health record (EHR), along with its mobile application, has demonstrated the ability to improve the efficiency and accuracy of health care delivery. This study included data from 874 health care providers over a 12-month period regarding their usage of mobile phone (EPIC® Haiku) and tablet (EPIC® Canto) mEHR. Ambulatory and inpatient care providers had the greatest usage levels over the 12-month period. Awareness of workflow allows for optimization of mEHR design and implementation, which should increase mEHR adoption and usage, leading to better health outcomes for patients.
Read More...A novel encoding technique to improve non-weather-based models for solar photovoltaic forecasting
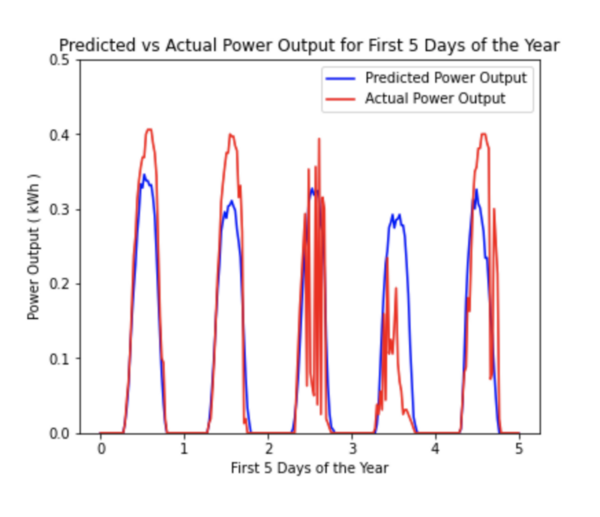
Several studies have applied different machine learning (ML) techniques to the area of forecasting solar photovoltaic power production. Most of these studies use weather data as inputs to predict power production; however, there are numerous practical issues with the procurement of this data. This study proposes models that do not use weather data as inputs, but rather use past power production data as a more practical substitute to weather-based models. Our proposed models demonstrate a better, cheaper, and more reliable alternatives to current weather models.
Read More...Employee resignation study in Fairfax County
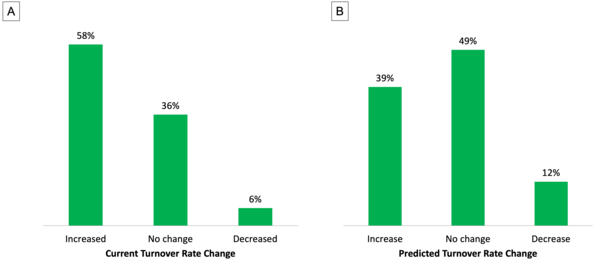
In this study, the authors address potential reasons why employees may voluntarily resign. This is in response to the currently observed economic trend The Great Resignation. Through analysis of federal and local government data along with survey results from Fairfax County, they concluded that adding additional benefits will help companies retain talented empolyees.
Read More...The effect of adverse childhood experiences on e-cigarette usage in people aged 18–30 in the US

Recently, e-cigarette usage has been increasing rapidly. Previous research has found that adverse
childhood experiences (ACEs) are correlated to cigarette usage. However, there is limited data exploring if ACEs affect vaping. Therefore, in this work, we investigated the effects of ACEs on e-cigarette usage and hypothesize that witnessing vaping in the house and facing ACEs would increase e-cigarette usage while education on the dangers of vaping would decrease e-cigarette usage. We found that different types of ACEs had different correlations with e-cigarette usage and that education on the dangers of vaping had no effect on e-cigarette usage.
Mask wearing and oxyhemoglobin saturation effects during exercise

Wearing face masks has become a common occurrence in everyday life and during athletics due to the spread of diseases. This study tested if masks would affect blood percent saturation of hemoglobin (SpO2) during treadmill exercise. The data analysis showed that mask type, time, and the interaction of mask type and time were significant results, regardless of physical ability. These results may assist athletes in understanding the differences between training and competing with and without a mask.
Read More...