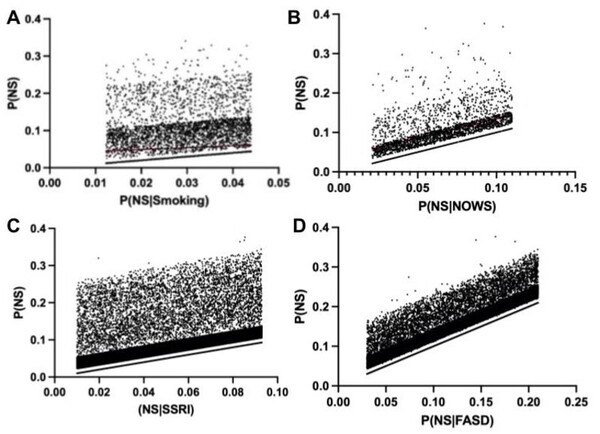
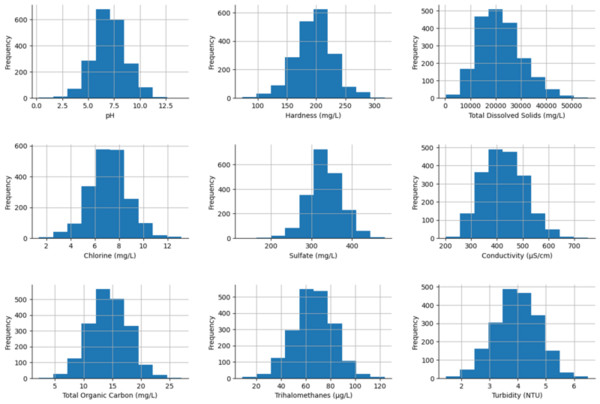
The global issue of water quality has led to the use of machine learning models, like ANN and SVM, to predict water potability. However, these models can be complex and resource-intensive. This research aimed to find a simpler, more efficient model for water quality prediction.
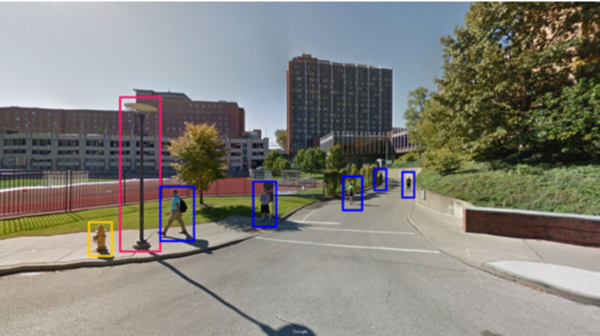
Every year, around 40% of undergraduate students in the United States discontinue their studies, resulting in a loss of valuable education for students and a loss of money for colleges. Even so, colleges across the nation struggle to discover the underlying causes of these high dropout rates. In this paper, the authors discuss the use of machine learning to find correlations between the built environment factors and the retention rates of colleges. They hypothesized that one way for colleges to improve their retention rates could be to improve the physical characteristics of their campus to be more pleasing. The authors used image classification techniques to look at images of colleges and correlate certain features like colors, cars, and people to higher or lower retention rates. With three possible options of high, medium, and low retention rates, the probability that their models reached the right conclusion if they simply chose randomly was 33%. After finding that this 33%, or 0.33 mark, always fell outside of the 99% confidence intervals built around their models’ accuracies, the authors concluded that their machine learning techniques can be used to find correlations between certain environmental factors and retention rates.
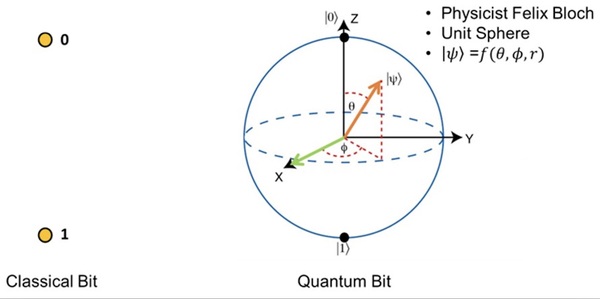
Current drug discovery processes can cost billions of dollars and usually take five to ten years. People have been researching and implementing various computational approaches to search for molecules and compounds from the chemical space, which can be on the order of 1060 molecules. One solution involves deep generative models, which are artificial intelligence models that learn from nonlinear data by modeling the probability distribution of chemical structures and creating similar data points from the trends it identifies. Aiming for faster runtime and greater robustness when analyzing high-dimensional data, we designed and implemented a Hybrid Quantum-Classical Generative Adversarial Network (QGAN) to synthesize molecules.
This article explored the question of when do people decide to stop gambling and further tries to extrapolate why people stop gambling at that point. Their study showed that people tend to quit gambling after 4 consecutive losses, significantly more than 1-3 consecutive losses or a win previous to quitting. They also found that participants commonly quit at a point value approximately 5 points greater than or less than their starting balance. The authors concluded that these results may be important in understanding how to cut down on excessive gambling or in creating policies that make it easier for people to disengage from gambling.
Here the authors sought to investigate whether and how cerebral stroke and other health-related variables are influenced together and amongst each other by using statistical analyses. Their analysis suggested relations between nearly all variables considered, with the strongest association between having heart disease and a cerebral stroke.
Middle school math forms the basis for advanced mathematical courses leading up to the university level. Large language models (LLMs) have the potential to power next-generation educational technologies, acting as digital tutors to students. The main objective of this study was to determine whether LLMs like ChatGPT, Bard, and Llama 2 can serve as reliable middle school math tutoring assistants on three tutoring tasks: hint generation, comprehensive solution, and exercise creation.
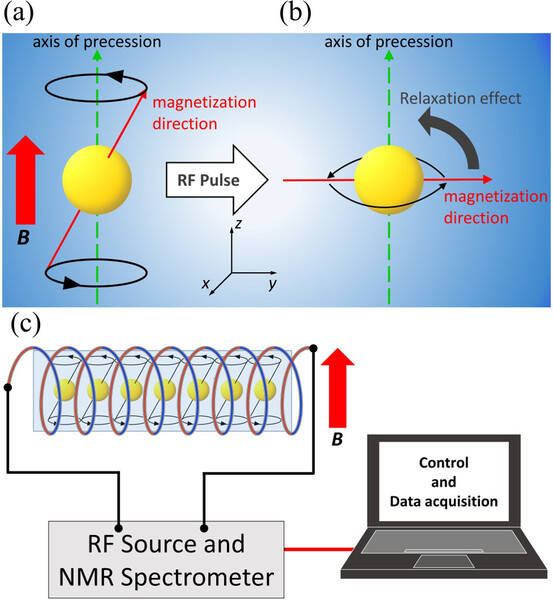
.png)