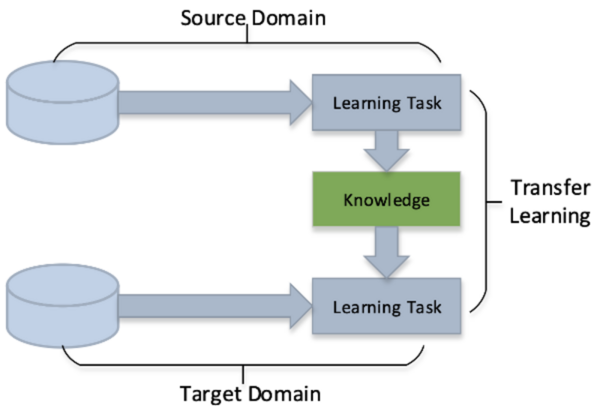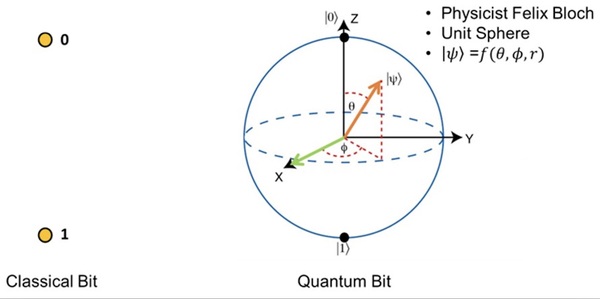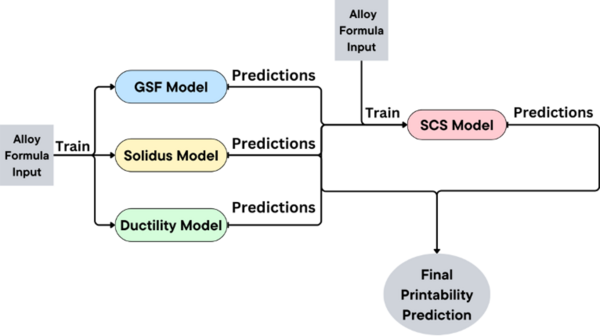
Additive manufacturing (AM) is transforming the production of complex metal parts, but challenges like internal cracking can arise, particularly in critical sectors such as aerospace and automotive. Traditional methods to assess cracking susceptibility are costly and time-consuming, prompting the use of machine learning (ML) for more efficient predictions. This study developed a multi-model ML pipeline that predicts solidification cracking susceptibility (SCS) more accurately by considering secondary alloy properties alongside composition, with Random Forest models showing the best performance, highlighting a promising direction for future research into SCS quantification.
Read More...