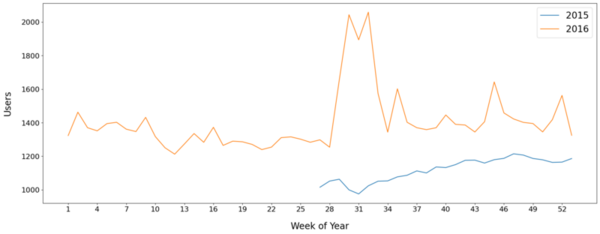
The authors looked at ways to provide better forecasting on website traffic. They found that deep learning models performed better than statistical models.
Read More...Deep sequential models versus statistical models for web traffic forecasting
The authors looked at ways to provide better forecasting on website traffic. They found that deep learning models performed better than statistical models.
Read More...Analyzing carbon dividends’ impact on financial security via ML & metaheuristic search

Impact of carbon tax and dividend on financial security
Read More...Simple solving heuristics improve the accuracy of sudoku difficulty classifiers
Risk-adjusted return measures for selecting optimal mutual fund investment portfolios
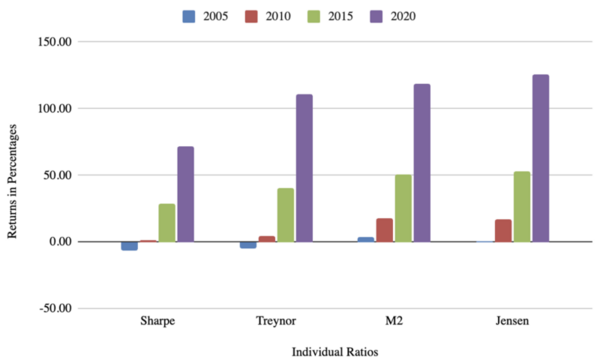
The authors looked at different combinations of risk-adjusted return measures to determine which combination would provide an optimal return for investors. They found that different combinations performed better dependent on investment timeframe.
Read More...A comparative analysis of machine learning approaches to predict brain tumors using MRI
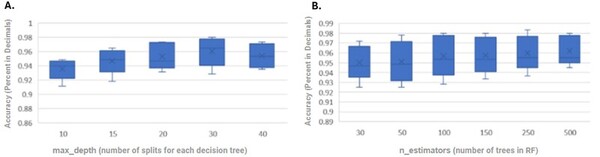
The authors use machine learning on MRI images of brain tissue to predict tumor onset as an avenue for early detection of brain cancer.
Read More...Long-run effects of minimum wage on labor market dynamics
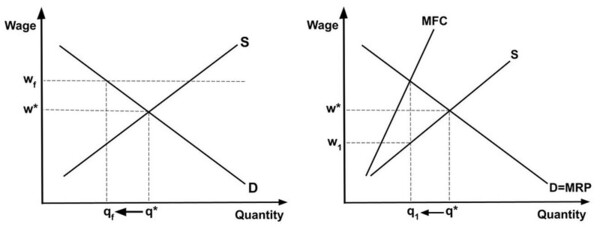
The authors looked at potential downstream effects of raising the minimum wage. Specifically they focused on taxable wages, employment, and firm counts.
Read More...SpottingDiffusion: Using transfer learning to detect Latent Diffusion Model-synthesized images
Understanding the battleground of identity fraud
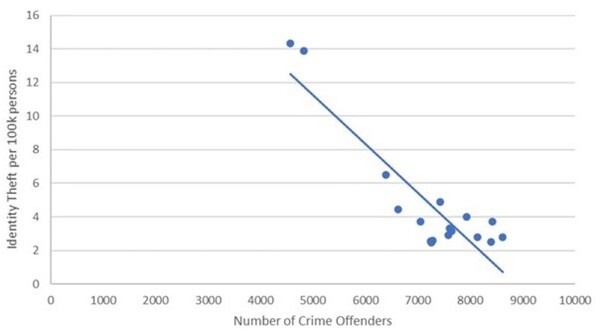
The authors looked at variables associated with identity fraud in the US. They found that national unemployment rate and online banking usage are among significant variables that explain identity fraud.
Read More...Evaluating the predicted eruption times of geysers in Yellowstone National Park
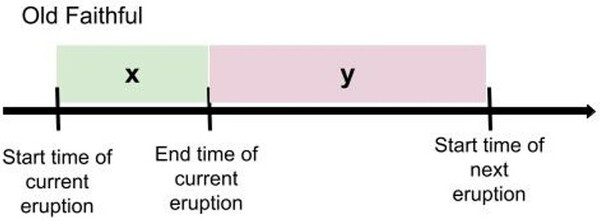
The authors compare the predicted versus actual geyser eruption times for the Old Faithful and Beehive Geysers at Yellowstone National Park.
Read More...Addressing and Resolving Biases in Artificial Intelligence
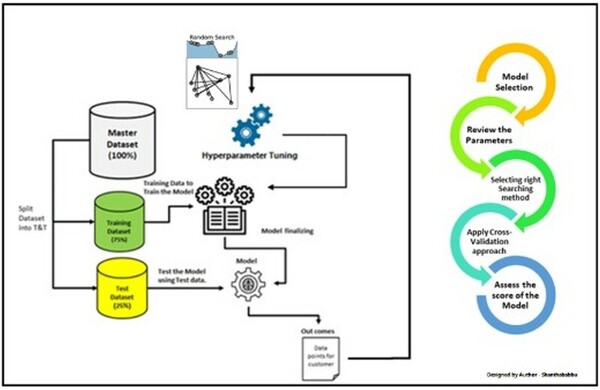
The authors explore how diversity in data sets contributes to bias in artificial intelligence.
Read More...