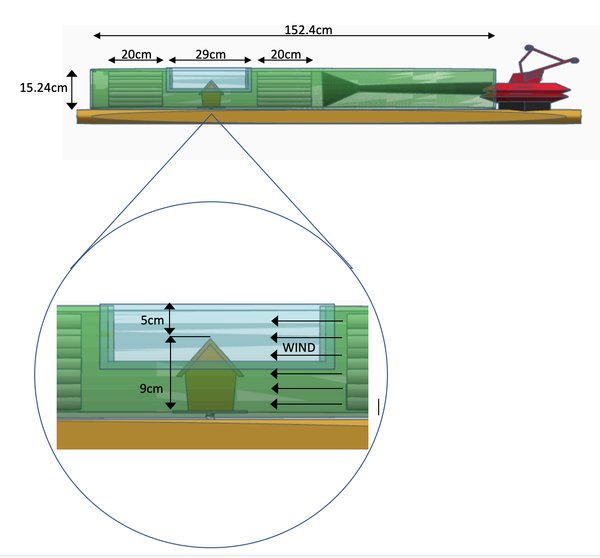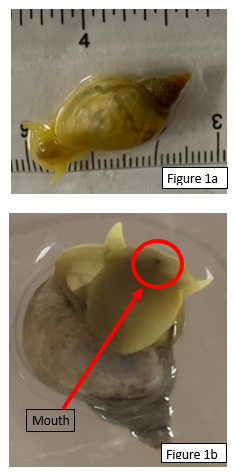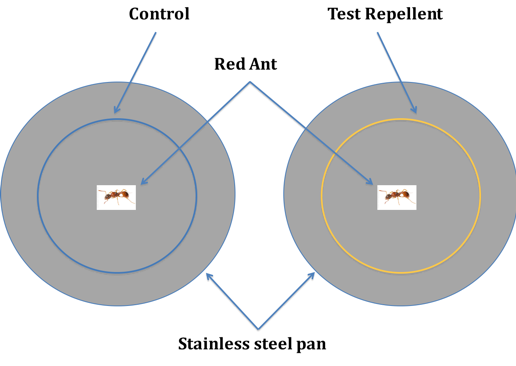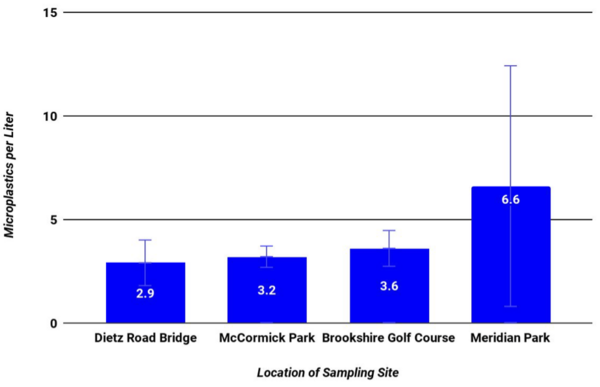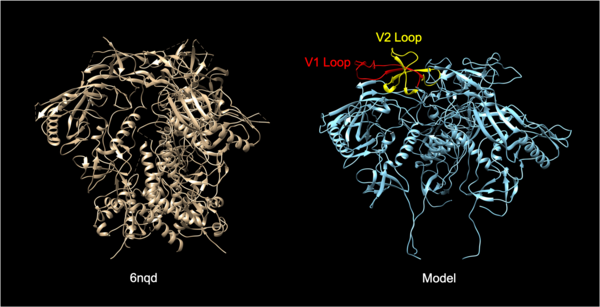
The Human Immunodeficiency Virus (HIV) infects approximately 40 million people globally, and one million people die every year from Acquired Immune Deficiency Syndrome (AIDS)-related illnesses. This study examined the interactions between the HIV-1 envelope glycoprotein gp120 and the human lymphocyte receptor integrin α4β7, the putative first long-range receptor for the envelope glycoprotein of the virus in mucosal tissues. Presented data support the claim that the V1 loop is involved in the binding between α4β7 and the HIV-1 envelope glycoprotein through molecular dockings.
Read More...